




Resolved: 400 Bad Request S3 Errors for Smoother S3 Operations
Amazon S3 is designed to handle large numbers of requests per second. For high-performance workloads, Amazon S3 is highly scalable, and there are no practical limits on the number of requests it can handle per second.
By Crystal / Updated on July 4, 2024
Causes of 400 Bad Request S3
400 bad request error is part of the HTTP status codes defined by the Internet Engineering Task Force (IETF) and typically occurs when the client sends a request that the server cannot process.
400 bad request error can occur in several scenarios:
- There are typos in the request URL, incorrect query parameters, or unsupported request methods.
- AWS credentials are incorrect or the IAM policies are not properly configured.

How to Troubleshoot Amazon S3 400 Bad Request
It's basic to check the request syntax, validate query parameters, and ensure that the correct HTTP method is used. Furthermore, you can try more troubleshooting steps using AWS CLI.
AWS Credentials
Incorrect AWS credentials can trigger a 400 Bad Request error. Double-checking the access keys and secret keys used in the requests ensures that they are valid and have the necessary permissions.
IAM Policies
IAM policies govern access to AWS resources. Misconfigured policies can prevent successful authentication, leading to errors. Reviewing and adjusting policies as needed can resolve these issues.
Log Analysis
Analyzing server logs provides insights into the root cause of the error. Logs can reveal details about the request processing and any issues encountered.
Using AWS CloudTrail
AWS CloudTrail offers comprehensive logging of AWS account activity, including API calls. It is a valuable tool for diagnosing and troubleshooting 400 Bad Request errors.
Free, Easy and Centralized Data Backup Solution
AOMEI Cyber Backup is a robust and reliable backup solution designed to meet the needs of businesses and individuals alike. It offers comprehensive data protection, ensuring that critical data is safe from loss due to hardware failure, cyber threats, or other unforeseen events. Below is a detailed introduction to AOMEI Cyber Backup:
🔰 Ease of Use: AOMEI Cyber Backup offers a user-friendly interface that simplifies the process of configuring backups to Amazon S3. This includes scheduling backups, setting retention policies, and monitoring backup status.
🔰 Comprehensive Backup Solutions: AOMEI Cyber Backup supports not only file and folder backups but also system backups and disk imaging.
🔰 Advanced Features: Features like incremental and differential backups help optimize storage space and reduce backup times.
🔰 Flexibility: AOMEI Cyber Backup's compatibility with Amazon S3 allows businesses and individuals to tailor their backup strategies according to specific needs, whether it's for disaster recovery, compliance, or simple data protection.
1. Click Target Storage > Amazon S3 > Add Target to open the add target page. Enter your Amazon S3 credentials including username, keyword, and bucket name, then click Confirm. Ensure you have the necessary permissions set up in your AWS account.

2. Click Backup Task > Create New Task to starting archiving your important data to Amazon S3. Select File Backup (for example) and choose files or folders for backup.
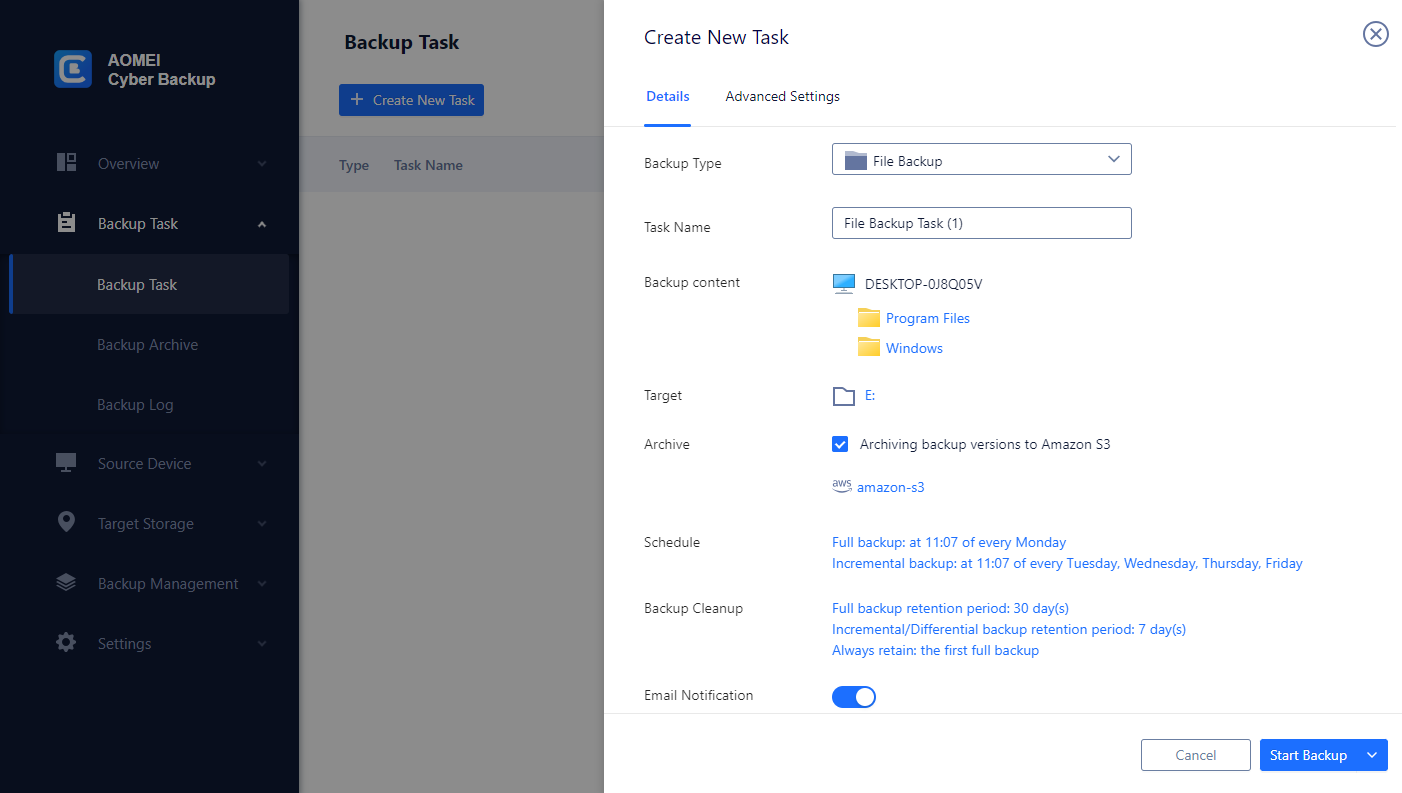
3. Check Archiving backup versions to Amazon S3 and click Select to choose the added Amazon S3.
4. Schedule backup task to run daily/weekly/monthly, and select backup retention policies to delete old backups automatically.
5. Click "Start Backup" to begin the backup process. It will first create a backup locally or on the NAS and then upload the backup to Amazon S3. According to the 3-2-1 backup rule, this ensures that the security of critical data and business continuity.
By leveraging AOMEI Cyber Backup to archive data to Amazon S3, you ensure a robust backup strategy that combines the reliability and scalability of S3 with the comprehensive backup capabilities of AOMEI Cyber Backup, thereby safeguarding your data against loss or corruption.
FAQs About 400 Bad Request Errors
Q: How many requests can S3 handle?
Amazon S3 (Simple Storage Service) is designed to handle large volumes of requests. It can manage thousands of requests per second for each prefix in a bucket. There are no strict limits on the number of requests, but performance can depend on various factors, such as request rates, object sizes, and distribution of requests. Amazon S3 automatically scales to accommodate increases in traffic.
Q: How do I fix access denied on S3?
"Access Denied" errors on Amazon S3 usually indicate permission issues.
1. Ensure that the bucket policy grants the necessary permissions for the user or role trying to access the bucket.
2. Ensure the IAM user or role has the appropriate permissions. Look for s3:ListBucket, s3:GetObject, and other relevant permissions in the IAM policy.
3. Access Control Lists (ACLs) on individual objects may override bucket policies. Make sure the object ACLs are configured correctly.
4. If you're trying to allow public access, ensure that the bucket’s public access block settings do not prevent it.
5. If accessing S3 from within a VPC, ensure that the VPC endpoint policy allows access to the bucket.
Q: What is the file size limit for S3 put request?
The maximum size for a single PUT operation in Amazon S3 is 5 gigabytes (GB). However, for uploading larger objects, you can use the Multipart Upload API, which allows you to upload parts of the object concurrently. This method supports the upload of objects up to 5 terabytes (TB) in size.
Conclusion
Understanding and resolving 400 Bad Request S3 errors is crucial for maintaining the reliability and performance of Amazon S3 operations. By following the troubleshooting steps in the article, you can minimize disruptions and ensure a smooth experience with Amazon S3.

