




How to Use S3 Glacier Deep Archive Storage Class [3 Methods]
If you have data that you don't need to access frequently but still want to keep secure, Glacier Deep Archive is the way to go. Let's dive into what it is, why it's important, and how you can get started.
By Crystal / Updated on May 31, 2024
What is Amazon S3 Glacier Deep Archive?
Amazon S3 Glacier Deep Archive, commonly referred to as just "Deep Archive," is a storage class within Amazon's Simple Storage Service (S3). It’s designed for data that you need to keep but don’t need to access often. Think of it as a super-secure, super-low-cost data vault in Amazon S3 Archive.
When it comes to archiving, cost and security are two critical factors. S3 Glacier Deep Archive excels in both.
- Lower Cost for Archiving: S3 Glacier Deep Archive is one of the cheapest storage options within AWS, making it perfect for large volumes of data that don't require frequent access.
- Long-Term Storage Solutions: If you need to keep data for years, even decades, Glacier Deep Archive is built for that.
- High Durability and Security: Glacier Deep Archive offers 11 nines of durability (99.999999999%). It also has strong security features, including encryption at rest and in transit.
Amazon S3 Glacier Deep Archive Storage Class
Amazon Glacier Deep Archive offers more secure and durable long-term storage at a competitive price, rivaling off-site tape archival services than Amazon S3 Glacier. Data is spread across at least three AWS Availability Zones, with retrieval times of 12 hours or less. This eliminates the need for costly tape drives, off-site storage, or complex data migrations.
Your existing S3-compatible tools, scripts, and lifecycle rules can integrate with Glacier Deep Archive. You can set this storage class when uploading new objects, change the storage class for existing objects manually or programmatically, or use lifecycle rules to transition objects to Glacier Deep Archive based on age. You can also utilize other S3 features like Storage Class Analysis, Object Tagging, Object Lock, and Cross-Region Replication for comprehensive data management.
How to Use S3 Glacier Deep Archive Storage Class [3 Methods]
Here are 3 methods to move data into S3 Glacier Deep Archive, using S3 AWS Management Console, Lifecycle Rules and CLI.
Using Glacier Deep Archive Storage on AWS Console
By following these steps, you can effectively switch the storage class of an existing S3 object to Glacier Deep Archive using the S3 Console.
1. Locate the file and click Properties > Storage class.

2. Select Glacier Deep Archive and click Save.
3. After making the change, confirm that the storage class has been updated to Glacier Deep Archive.
📢 Note: This change may take some time to propagate, especially if there are many objects or if other processes are running on the S3 bucket.
Using Glacier Deep Archive Storage – Lifecycle Rules
To automate transitions to Glacier Deep Archive, consider setting up lifecycle policies. This can be especially useful for large-scale data management.
1. Click Management tab.
2. Select Add lifecycle rule and set up as following.
- Give your rule a unique name.
- Specify if you want the rule to apply to all objects in the bucket, or only to objects with a specific prefix or tag.
- Select Current version and choose "Transition to Glacier Deep Archive 30 days after".
Using S3 Glacier Deep Archive – CLI / Programmatic Access
1. Use the CLI to upload a new object and set the storage class:
2. Change the storage class of an existing object by copying it over itself:
How to Backup Data to S3 Glacier Deep Archive
By integrating with Amazon S3 Glacier Deep Archive, AOMEI Cyber Backup helps you leverage one of the most cost-effective long-term storage solutions available, ideal for infrequently accessed data. Here are some compelling reasons to use AOMEI Cyber Backup for backing up data to Amazon cloud:
- Comprehensive Backup Options: AOMEI Cyber Backup supports various backup types, including full, incremental, and differential backups, ensuring you can tailor your backup strategy to your specific needs.
- Ease of Use: The software features an intuitive interface, making it easy to set up and manage backups without requiring extensive technical knowledge.
- Automation and Scheduling: AOMEI Cyber Backup allows you to schedule backups to run automatically at specified times, ensuring your data is consistently protected without manual intervention.
- Reliability: AOMEI Cyber Backup is known for its reliability and robust performance, reducing the risk of backup failures and ensuring your data is always safe.
This guide will walk you through the steps to back up your data to Amazon S3 Glacier Deep Archive using AOMEI Cyber Backup. Download the professional backup software from the button below:
1. Click Target Storage > Amazon S3 > Add Target to open the add target page. Enter your Amazon S3 credentials including username, keyword, and bucket name, then click Confirm. Ensure you have the necessary permissions set up in your AWS account.

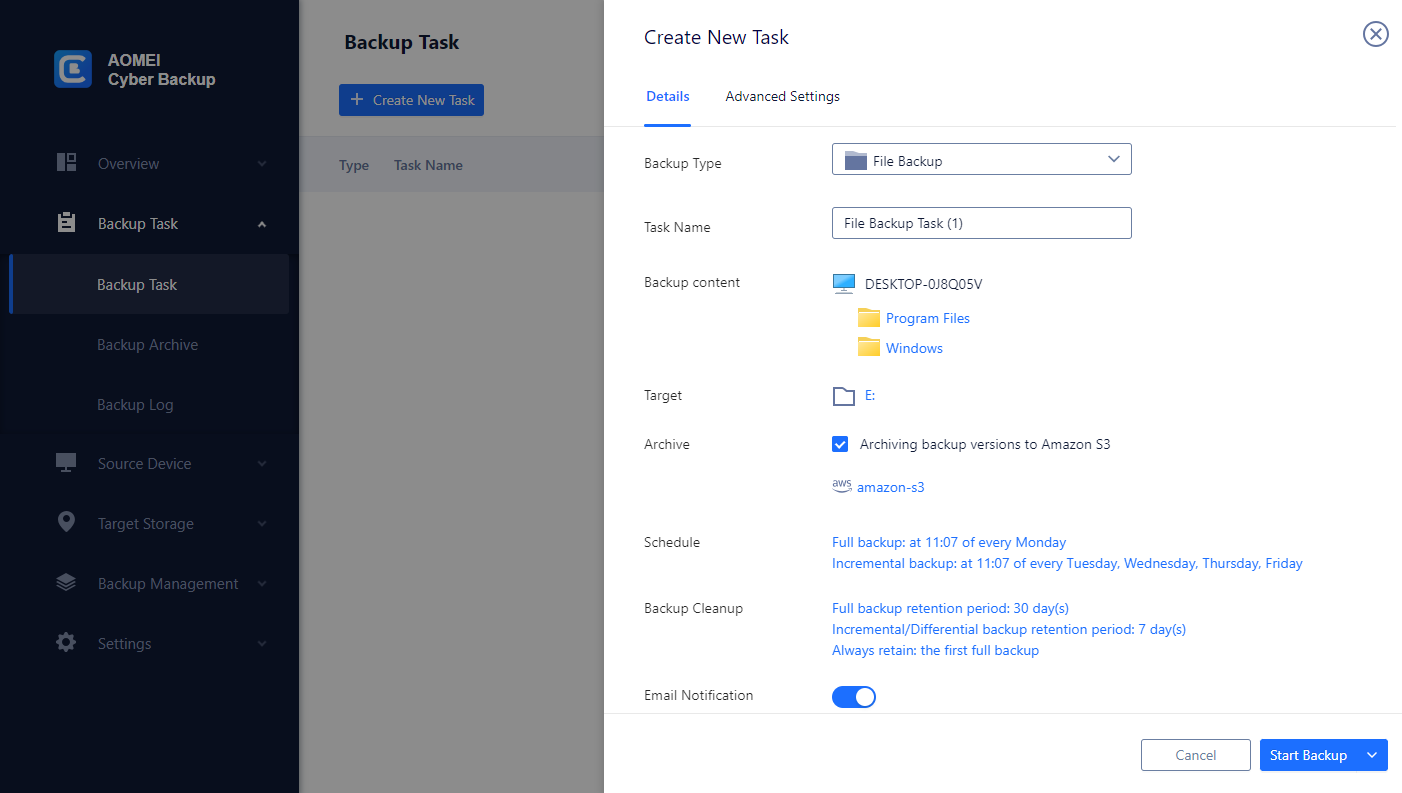
2. Click Backup Task > Create New Task to starting archiving your important data to Amazon S3. Select File Backup (for example) and choose files or folders for backup.
3. Check Archiving backup versions to Amazon S3 and click Select to choose the added Amazon S3.
4. Schedule backup task to run daily/weekly/monthly, and select backup retention policies to delete old backups automatically.
5. Click "Start Backup" to begin the backup process. It will first create a backup locally or on the NAS and then upload the backup to Amazon S3. According to the 3-2-1 backup rule, this ensures that the security of critical data and business continuity.
FAQs on S3 Glacier Deep Archive
Q: How much does S3 Glacier Deep Archive cost?
A: It's among the cheapest storage options on AWS, with low per-gigabyte rates. Costs depend on data volume, retrieval frequency, and retrieval size. Additional fees apply for expedited retrievals.
Q: How secure is my data in S3 Glacier Deep Archive?
A: Data in Glacier Deep Archive is encrypted at rest and in transit. AWS provides additional security through Identity and Access Management (IAM), access controls, and server-side encryption. The service also offers audit logs and monitoring.
Q: How quickly can I retrieve data from Glacier Deep Archive?
A: Standard retrievals take 3–5 hours, while expedited retrievals (for a fee) can take 1–5 minutes. Bulk retrievals, designed for large data sets, can take 5–12 hours.
Q: What file types can be stored in S3 Glacier Deep Archive?
A: You can store any file type, including text documents, images, videos, and large data sets. This flexibility makes it suitable for a wide range of storage needs.
Conclusion
Here are 3 methods for you to move data to S3 Glacier Deep Archive in AWS, ensuring it's stored in a more cost-effective manner. It's ideal for long-term storage and infrequent access, unlike S3 Standard or S3 Intelligent-Tiering, which offer faster access but at a higher cost.

